So I got this video from a friend, and I wanted to post it on my site, but I wanted to do it without using any Flash, or any plugins, and I wanted it to work on the iPhone, and Chrome, and Firefox, and IE…
Step 1: Convert the file.
First I took the file and used Miro Video Converter to make two versions of the file. The first version I made was using the “Theora” format. This is an Ogg format, and you basically only need to make it for the video to show up in Firefox. Future versions of Firefox will support the WebM format instead (Chrome supports it now), so when Firefox 4 comes out, use that format. Next, use Miro again and this time make a version using the iPhone preset. This basically creates an MP4 version of the file, but at the right resolution to have it show up on the iPhone. Annoyingly, the original file was from an iPhone, so it should have played, but it wouldn’t on mine. I suspect that the resolution difference between the iPhone 4 (used to make the photo) and the iPhone 3GS (which I have) is the problem. Regardless, I just used the preset to downscale the video resolution.
Step 2: Adjust WordPress’ settings
WordPress didn’t like me uploading these files. Turned out that it was because I’m on multisite. In the Network Admin screen, find the Network Settings menu option, go to the bottom of the page, and add the mp4 and ogv extensions to the list of allowed files. Also add webm while you’re there, for the future. Note: If you’re not on multisite but still have problems uploading the files, then add this line of code to your wp-config.php file, to turn on the unfiltered_upload capabilities for administrators:
define('ALLOW_UNFILTERED_UPLOADS',true);
Step 3: Check .htaccess settings
One of the things WordPress relies on to know if it’s a video or not is the MIME Type. Some servers have these properly configured, some don’t. Doesn’t hurt to help the process along by explicitly defining some of them in the .htaccess file. For good measure, I added a bunch of common ones, just to be sure:
There’s a few things there you’ll need to manually edit. Obviously the URLs need to point to your files. Also, it’s important that the MP4 one is first, some older iPad software doesn’t like it otherwise. The second one is the width and height. Now, like with posting images, these don’t have to exactly match the actual width and height of the video. The browser will use these sizes and scale the video accordingly. However, you’ll want to get the aspect ratio correct, so you don’t stretch or squish the video into the wrong sized box. And you can leave the height and width out entirely to not scale it, if you got your sizes correct in the video itself. But it’s a good idea to have them there regardless, to clue the browser into the size beforehand and speed up page rendering. Also note that the iPhone doesn’t care about those width and height tags, since it will just show the video full screen when you tap on it. Sidenote: Do NOT switch into Visual mode. TinyMCE will muck up this code, badly, and try to add a SWF player to it and Flash and a bunch of other stuff. This is probably by design, but I wanted to do this without Flash at all and see how that worked. Turns out to work fine in the browsers I tested. Finally, preview and publish as normal.
Wantlist
One thing I haven’t figured out is how to target the iPhone specifically with a separate file. With this setup, Chrome and IE are now showing the iPhone file, which is lower resolution than the OGV file (which is at original resolution). In this specific case, the video was poor and so it doesn’t make much difference, but I’d prefer to have a separate file specified that only iPhones used without having to resort to user agent targeting. EDIT: Turns out you can do this with a media query on the source that targets the iPhone. So here’s my new code:
The media attribute lets you specify a CSS3 Media Query. The max-device-width of 480px = iPhone. So desktop browsers will use the video.mp4 while the iPhone uses the video.iphone.mp4. I’ve confirmed that this works properly with Chrome. It’s interesting to see that browsers can do this reasonably well, even if you do have to make a few different versions of the video.
Shortcode Plugin
At the suggestion of ipstenu in the comments below, I made this into a shortcode plugin. You can download it here: HTML5 Video Shortcode. This plugin has the advantage of being ignored by TinyMCE.
El investigador, Sam Croley, experto en cifrado de contraseñas y desarrollador principal en Hashcat, dijo que la GPU RTX 4090 alcanzó velocidades récord de 300GH/seg. y 200kh/seg. Un sistema de 8 RTX 4090 podría probar 200 mil millones de combinaciones de contraseñas de ocho caracteres en solo 48 minutos en la modalidad de fuerza bruta y utilizando HashCat.
En 2011, el investigador de seguridad Steven Meyer demostró que una contraseña de ocho caracteres (53 bits) podría forzarse por fuerza bruta en 44 días, o en 14 segundos si usa una GPU y tablas arcoíris: tablas precalculadas para invertir funciones hash.
Ahora, en las nuevas pruebas, el equipo de IT Pro atacó el protocolo de autenticación NTLM (New Technology LAN Manager) de Microsoft, muy utilizado en las redes empresariales para autenticar la identidad de los usuarios, y también con la función Bcrypt de uso común para el descifrado de contraseñas.
La que un investigador expresó su asombro ante los resultados de una comparativa, donde la tarjeta alcanzó “una mejora demencial de más de 2 veces con respecto a la tarjeta predecesora, la 3090, en casi todos los algoritmos.
La publicación también cita un tuit, a cuyo juicio un equipo equipado con ocho GPU RTX 4090, permitiría a un intruso probar todas las combinaciones (200.000 millones) de contraseñas de ocho caracteres en solo 48 minutos utilizando métodos de fuerza bruta. Esto es mucho más rápido que las dos horas y media que se tardaría en conseguir los mismos resultados con la 3090, la anterior tarjeta insignia de NVIDIA, e incluiría contraseñas con mayúsculas, minúsculas, símbolos y números aleatorios.
A 1.699 euros por unidad, sigue siendo un hardware enfocado al consumidor y ampliamente disponible en el comercio. “Esto puede hacer que la GPU sea una inversión valiosa para los actores de amenazas, que ahora pueden potenciar sus sistemas de intrusión a través de canales legítimos”, escribe la publicación.
Sin embargo, los expertos que hablaron con IT Pro recalcan que hay limitaciones para este tipo de ataques en el mundo real, incluso con un hardware potente que los respalde. “Este tipo de dispositivos suele utilizarse para descifrar contraseñas offline, ya que las soluciones online suelen ser resistentes a este tipo de vectores de ataque”, comentó Grant Wyatt, director de operaciones de MIRACL.
Dado que la mayoría de las contraseñas creadas por los usuarios no son secuencias aleatorias, sino que tienden a seguir patrones de palabras de uso común, los atacantes pueden en la práctica llegar a la contraseña correcta mucho antes. Si una RTX 4090 recorriera una lista de sólo los cientos de contraseñas más probables para una cuenta, podría hacerlo en milisegundos.
El experto puso de relieve que el riesgo es especialmente alto para las contraseñas que se comparten entre los empleados y que son fáciles de recordar. Los ataques de diccionario funcionan precisamente así, con un equipo que utiliza una lista de las contraseñas más comunes y palabras dentro de las contraseñas para acelerar el proceso de fuerza bruta.Fuente: ITPro
Es probable que, en alguna ocasión, te hayas encontrado con las siglas ‘VPN’. Su significado es ‘Virtual Private Network’ o, en español, ‘Red Privada Virtual’; un nombre adecuado para nombrar una tecnología que, fundamentalmente, trata sobre crear un ‘mini-internet dentro de Internet’ que conecta directamente dos o más dispositivos, aunque no estén físicamente conectados entre sí.
Y, además, lo hace encriptando los datos que esos dispositivos intercambian a través de la red, por lo que evita que puedan ser interceptados. Suma a eso que oculta tu dirección IP —los sitios web a los que intentes conectarte recibirán la petición desde el servidor VPN, no desde tu equipo— y sabrás por qué quienes valoran la privacidad y seguridad de su conexión suelen recurrir a esta herramienta.
Ojo, no es que garantice un anonimato absoluto: tu proveedor de Internet podrá saber que estás conectado a esa VPN, pero ciertamente no podrá saber a dónde te conectas ni qué haces desde la misma.
Además, nuestro proveedor de Internet no puede acceder a nuestras comunicaciones, pero el propio servidor VPN sí podría hacerlo si resultara ser malicioso: por eso es tan importante hacer uso de un servicio VPN fiable
Así funciona:
Cuando nos conectamos a un servicio VPN, la conexión se establece entre un software cliente y un servidor VPN online. Para ello, se pueden usar varios protocolos de tunelización que varían entre sí en aspectos como la estabilidad o la velocidad de la conexión.
Una vez establecida la conexión (previa autenticación, habitualmente), el servidor aplica un protocolo de cifrado a todos los paquetes de datos que intercambia con el cliente.
Dichos paquetes se introducen en otros paquetes externos en un proceso conocido como encapsulación, para reforzar la seguridad de los datos. Estos paquetes encapsulados son los que viajan por el ‘túnel’ VPN y sólo se ‘desembalan’ en cada uno de los extremos receptores de la conexión.
El uso de VPNs cuenta con una desventaja obvia: una conexión a Internet más lenta (cada paquete de información debe pasar ahora por un servidor intermedio)
Antecedentes…
El origen de la tecnología VPN se remonta a 1996, cuando un empleado de Microsoft, Gurdeep Singh-Pall, desarrolló el primer protocolo de tunelización, el PPTP (siglas de ‘peer-to-peer tunneling protocol’). En un primer momento, el uso de esta tecnología se enfocó únicamente a los entornos corporativos, necesitados de medidas de seguridad adicionales ante la necesidad de abrirse al recién creado Internet.
Sin embargo, con el auge tanto de los ciberataques como de los sistemas de cibervigilancia desde el comienzo de este siglo, cada vez más gente se hizo consciente de las ventajas de su uso para los usuarios individuales. Más tarde, entre 2016 y 2018, el número de usuarios de VPN en todo el mundo llegó a cuadruplicarse —según el GlobalWebIndex—. Pero, ¿para qué es usada esta tecnología?
Habitualmente, accederemos a los servicios VPN instalando la aplicación (móvil o para PC) específica de cada uno, pero a veces es posible usarlos mediante extensiones del navegador… ¡o hasta configurándolos en nuestro router!
¿Por qué necesito una VPN?
Porque utilizas regularmente redes WiFi públicas: Esta clase de redes WiFi (habituales en hoteles, aeropuertos, cafeterías y transportes públicos) son inseguras por definición, y exponen a quien se conecta a ellas a la posibilidad de que haya un ciberatacante ‘escuchando’ (mediante técnicas de análisis de paquetes) o manipulando (mediante un ataque man-in-the-middle) sus comunicaciones. Nada de eso es posible si el tráfico web permanece tunelado y encriptado gracias a una VPN.
Porque quieres acceder a contenidos censurados y/o restringidos geográficamente: Habitualmente las autoridades, motivadas por normativas sobre seguridad nacional, protección del copyright o similar, son capaces de impedirnos acceder a determinadas páginas y servicios online, y en otros casos son dichos servicios los que desean restringir el acceso de conexiones procedentes de determinados países. Pero, cuando nos conectamos a través de una red virtual privada, la conexión al servidor web se realiza desde una IP de país donde se localiza el servidor VPN, por lo que los bloqueos por criterios geográficos pierden toda efectividad.
Es habitual usar VPNs para, por ejemplo, acceder a contenidos de servicios de streaming que problemas de licencias impiden visualizar en nuestro propio país
Porque trabajas en remoto: Muchas empresas ya exigen el uso de servicios VPN a la hora de otorgar acceso a su red corporativa a los empleados que se conectan desde el exterior. Una conexión en la que no mediase el cifrado de la VPN sería vulnerable a un robo de credenciales, lo que podría poner en peligro la seguridad de toda la empresa (y la confidencialidad de sus datos).
Si eres streamer y/o gamer: Ya hemos dicho que una VPN oculta qué dirección IP estamos usando. Y lo que la gente no conoce, no lo puede atacar: tanto el mundo de los videojuegos como el streaming puede ser muy competitivo cuando hay dinero de por medio, y no es raro que se lleven a cabo ataques DDoS con el fin específico de hacer caer una conexión durante una emisión o una partida.
¿Cuál es la mejor VPN gratis?
Si bien recurrir a aplicaciones VPN de pago suele considerarse la mejor solución, existen diversos servicios VPN gratuitos fiables y conocidos, incluso si normalmente alguna de las características del servicio que presten sea inferior a las de las primeras (puede imponer limitaciones en la velocidad, en la cantidad de datos, en el número/variedad de ubicaciones disponibles, etcétera).
Puedes comprobar cuál se ajusta más a tus necesidades accediendo a nuestro reciente artículo ‘VPN gratis: en cuáles puedes confiar y en cuáles no‘.
En el caso de que quieras recurrir a un servicio VPN de terceros, sólo tienes que instalar su aplicación correspondiente en Windows, abrirla y pulsar el preceptivo botón de ‘Conectar’ (en el caso de que no lo haga automáticamente). Eso sí, puede que antes te pida configurar alguna opción (depende de cada app, y existen docenas y docenas).
Existe también un botón de ‘Agregar VPN’ en ‘Configuración de Windows > Red e Internet > VPN‘, pero sólo necesitaremos recurrir a ese apartado si nos da por crear nuestra propia VPN. Si te interesa, sigue leyendo…
¿Cómo crear una VPN?
Aunque hay multitud de servicios VPN de terceros, no necesitas recurrir a ninguno de ellos para conectarte a través de una conexión VPN: puedes crear tu propia red virtual doméstica. Windows, sin ir más lejos, nos facilita (bueno, dejémoslo en ‘permite’) realizar esa tarea. Por supuesto, esa red no nos servirá para hacer pasar tu IP por extranjera, porque te estarás conectando igualmente desde España, pero sí puede proteger tu privacidad, tunelizando tus datos y enmascarando la IP de tu router cuando te conectes.
Para crearla, bastará con acceder a ‘Red e Internet’ dentro de la Configuración de Windows. En Windows 10 deberemos pulsar ‘Estado > Cambiar opciones del adaptador‘, mientras que en Windows 11 iremos a ‘Configuración de red avanzada > Más opciones del adaptador de red‘. En ambos casos, se nos abrirá la misma ventana del antiguo ‘Panel de Control’, una que nos mostrará las conexiones que tengamos creadas. Allí, pulsaremos F10 para mostrar un menú oculto con más opciones, que nos permitirá hacer clic en ‘Archivo > Nueva conexión entrante‘.
Al hacerlo, nos aparecerá una ventana titulada “¿Quién puede conectarse a este equipo?” y un listado de cuentas de usuario; debajo, tendremos un botón de ‘Agregar a alguien’ que nos permitirá crear una cuenta de usuario y establecer su contraseña. Hazlo: los datos que establezcas serán los que nos permitirán crear la coenxión VPN después.
Una vez creado, pasarás a una pantalla en la que Windows preguntará cómo se va a conectar este usuario a tu red: debes seleccionar la opción ‘A través de Internet’. Así, el nombre de usuario que has creado será para conectarse a la red formando una VPN. Tras pulsar en ‘Siguiente’, pasaremos a otra pantalla que nos mostrará protocolos de red. Aquí, tienes que seleccionar la opción ‘Protocolo de Internet versión 4’ y pulsar en ‘Propiedades’.
¿El objetivo? Evitar que la nueva conexión utilice nuestra IP por defecto, y cambiarla por un nuevo rango de IPs que estén dentro de tu dirección IP. Tranquilo, te lo iremos explicando. Lo primero, selecciona la opción ‘Especificar direcciones IP’. Ahora, vete a ‘Inicio > Ejecutar’ y abre una aplicación llamada ‘ipconfig’: se abrirá una ventana de terminal mostrando varias direcciones IP; apunta la ‘Puerta de enlace predeterminada’ (la IP de tu router) y vuelve a donde estábamos para escribir las mismas tres primeras series de números… pero luego cambia el último número indicando un rango de IPs tan amplio como IPs quieras asignar a tu VPN.
Si la IP de nuestro router fuera ‘99.99.99.1’, un ejemplo del rango de IPs que podríamos proporcionarle a la configuración en este punto sería la del ejemplo.
Una vez escrito el rango de IPs, pulsa en ‘Aceptar’, y volverás a la pantalla de software de red. Aquí ya habrás terminado de configurarlo todo, por lo que solo te queda pulsar en el botón de ‘Permitir acceso’, y Windows procederá a crear tu servidor VPN. Tras eso, deberás entrar en la configuración de tu router para abrir el puerto 1723 creando una nueva ‘regla manual’; te pedirá la dirección IP de tu PC (no la de tu router), por lo que debes volver a abrir ‘ipconfig’ y apuntar el dato ‘Dirección IPv4’.
Cuando hayas terminado allí, debes acceder a ‘Panel de Control > Sistema y seguridad > Firewall de Windows Defender > Permitir que una aplicación o una característica a través de Firewall de Windows Defender‘. Ahí, pulsaremos en el botón de ‘Cambiar la configuración’ y aceptaremos dar permisos de administrador. Aquí, tienes que activar las casillas Privada y Pública de la opción de Enrutamiento y acceso remoto, que aparece en la lista.
Ahora, vuelve a abrir ‘ipconfig’ y apunta la nueva ‘Dirección IPv4’, vete a ‘Configuración > Red e Internet > VPN‘ y, tras pulsar en el botón ‘Agregar VPN’, indica esta nueva dirección IP. En la nueva ventana que se te abra elige ‘Windows’ como ‘Proveedor de VPN’, en ‘Nombre de servidor o dirección’, la primera ‘Dirección IPv4’ que te salió y finalmente escribe el nombre de usuario y contraseña que creaste al comienzo de este proceso. ¡Listo, ya tienes tu conexión VPN en marcha!
Una VPN que recomendamos
NordVPN es uno de los líderes del sector VPN; numerosos websites de reseña de VPN lo señalan hoy en día como la mejor opción del mercado. También es uno de los veteranos del sector: lanzó su servicio hace ahora 10 años, cuando contaba con sólo 6 servidores (hoy en día cuenta con 5.200, repartidos por 59 países). Pero nuestras razones para recomendarlo son otras:
Privacidad: NordVPN tiene su sede en Panamá, un país con fama (y leyes para respaldarla) de proteger la privacidad de las empresas. Además, sus servidores carecen de unidades de disco, realizando almacenamiento virtual en RAM, lo que les impide recopilar datos de navegación de sus usuarios y garantiza la privacidad de nuestra navegación.
Velocidad: Además, la última comparativa de velocidad de servicios VPN publicada por AVTest situaba la velocidad de descarga de NordVPN muy (muy) por encima de la de sus principales rivales, prácticamente no notarás que estás usando un VPN mientras navegas.
Posted by MuSsUtO JoRgE® |
May 10, 2020 | Categories: Systems Computers U.S.A. Inc. | Comments Off on Pones el nombre de un musico o grupo y sale toda su discografia gratis para escuchar y descargar ¡Disfrútalo!
Posted by MuSsUtO JoRgE® |
May 10, 2020 | Categories: Systems Computers U.S.A. Inc. | Comments Off on Gonzalo Garcia Pelayo de “Los Pelayo” ofrece una alternativa económica a los actuales periodos de escasez
Posted by MuSsUtO JoRgE® |
May 4, 2020 | Categories: Systems Computers U.S.A. Inc. | Comments Off on LISTA DE PERSONAS CONOCIDAS CONECTADAS A CULTOS SATÁNICOS Y PEDOFILIA (PRESUNTAMENTE CLARO)
Posted by MuSsUtO JoRgE® |
May 3, 2020 | Categories: Systems Computers U.S.A. Inc. | Comments Off on ¿Miles de niños liberados del secuestro por parte de miembros de la élite mundial????
Ha pasado más de un año desde que entrara en vigor el cumplimiento obligatorio del Reglamento General de Protección de Datos (GDPR) y sin embargo, la sensación que nos queda es que poco o nada ha cambiadomás allá de aquel aluvión de emails que recibimos y los avisos de cookies y nuevas políticas de privacidad.
Si los mismos expertos no ven que se haya productido una mejorsa sustancial en ningún aspecto, y creen que la normativa no ha sido entendida ni aplicada por la mayoría de las empresas, los usuarios están aún más lejos de comprender del todo cuáles son sus derechos y cómo los protege la ley frente a la inmensa recolección de sus datos a la que se ven sometidos a diario. De este predicamento ha nacido el proyecto mydatamood.
Este sitio funciona como un intermediario para que cualquier usuario pueda ejercer a través de ellos sus derechos sobre los datos que las empresas recolectan.
Hagamos un nuevo contrato
La iniciativa de mydatamood fue creada por un grupo de profesionales españoles especializados en el área legal, de marketing e ingeniería, como una solución para aquellos usuarios que están preocupados por la privacidad de sus datos personales.
Bajo la propuesta de lo que han llamado el #NewDataDeal, el equipo conformado por Dany Bertolín, Sabina Guaylupo, y Ángela Álvarez buscan ayudar a establecer un nuevo contrato social entre las empresas y los usuarios.
En Genbeta hemos hablado con sus creadores y hemos conocido en detalle qué es lo que buscan, cómo pueden ayudarte a obtener más control sobre tus datos haciendo valer tus derechos legales, y qué esperan obtener a cambio.
Ayudar a los David que se quieren enfrentar a un Goliat
Si bien la GDPR llegó para proteger a los ciudadanos europeos de las empresas que hacen un mal uso de nuestros datos, siguen existiendo empresas que se resisten a seguir las reglas. Como usuario tienes derecho de acceder y gestionar todos los datos que cualquier tercero haya recolectado por ti, pero en muchos casos el proceso es tan complicado, y las empresas colaboran tan poco, que muchos se rinden o ni siquiera lo intentan.
Es una clásica historia de David contra Goliat, ¿quién tiene el tiempo, los recursos y el conocimiento para luchar contra una empresa gigante? La misma OCU lleva más de un año intentando demandar a Facebook para que pague a los españoles por el escándalo de Cambridge Analytica.
Ángela Álvarez, licenciada en psicología y una de las fundadoras de mydatamood, nos explica: “Esto surge de lo que le preocupa a todo el mundo, que es qué pasa con mis datos, pero que cae en un grupo de personas que tenemos más información que el resto sobre lo que está pasando con los datos”.
“La normativa de la GDPR no sirve para nada si los ciudadanos no ejercen sus derechos”
Ángela nos cuenta que con el proyecto tienen como objetivo principal la sensibilización masiva, puesto que necesitan que haya una masa crítica de gente que sea consciente de lo que está pasando con sus datos, de que sepan el valor que tienen sus datos y de que las empresas se están aprovechando de ellos y de que eso es algo que al final tendrá consecuencias a largo y mediano plazo.
“La normativa de la GDPR no sirve para nada si los ciudadanos no ejercen sus derechos. A Movistar, que una persona individual le diga que tiene derecho a saber que están haciendo con sus datos, le da lo mismo. Ahora, si tiene a cien mil personas detrás, entonces ya tienen un problema”.
Básicamente, en la unión está la fuerza. Mientras más usuarios se unan a la iniciativa del #NewDataDeal, más presión colectiva se puede ejercer. Ellos suman el conocimiento y la experiencia, y tú sumas a los números.
Actualmente no hay equilibrio, las empresas controlan todo este enramado y los ciudadanos ni se enteran, ni saben cómo cambiar esa situación, porque no saben qué derechos tienen ni cómo ejercerlos
Por supuesto, mydatamood también busca un beneficio en todo esto, no un proyecto filantrópico, también es un negocio, porque necesita serlo para poder ser sostenible. En eso han sido muy transparentes: “Lo que nosotros queremos hacer, para que funcione, necesita de esa masa crítica de usuarios, necesitas hacerlo bien y necesitas dinero”.
El plan para hacer rentable mydatamood es el de encontrar un equilibrio entre sensibilizar al público y ofrecer un servicio viable económicamente. Ellos facilitan de forma gratuita una serie de recursos que te ayudan a ejercer tus derechos, pero si quieres ir más allá y llevar acciones legales, puedes disponer de sus servicios pagando.
Si al final quieres poner una reclamación a la Agencia de Protección de Datos, o si quieres que le insistamos a una empresa para que borren algo, habrá otra serie de derechos que quién quiera que le ayudemos a ejercerlos, pues tendría que pagar. Como cualquier plataforma de negocio escalable, vas a pagar mucho menos si lo haces a través de una plataforma que se dedica especialmente a ello y que tiene un sistema automatizado, que si te vas a un despacho de abogados
Por ahora, si te unes a mydatamood como un “mooder”, te regalan 50 de lo que han llamado “mooins”. Con esos mooins puedes reclamar tus datos (10 mooins por solicitud). Con eso puedes empezar, y proximamente ofrecerán más servicios como rectificación de datos erroneos, eliminación de datos, y hasta formas de rentabilizar tus propios datos.
La ventaja aquí es que si no sabes cómo reclamar algo, ni a dónde acudir, ni qué derechos tienes, mydatamood pone todo eso a tu alcance a través de un equipo especializado y prometen hacerlo con una “oferta muy barata, muy tarifa plana”.
En estos momentos solo las empresas se benefician de los datos que recolectan, en mydatamood tienen claro que esos datos tienen valor, especialmente valor ecónomico, y si logran amasar una buena cantidad de usuarios para ejercer suficiente presión utilizando los recursos legales que dominan y que escapan al usuario individual, podrían lograr crear ese nuevo acuerdo en el que se beneficien también los usuarios.
La recolección de datos no va a detenerse pronto o probablemente, nunca. Pero hoy, la balanza está completamente del lado de un bando.
Posted by MuSsUtO JoRgE® |
August 15, 2019 | Categories: Systems Computers U.S.A. Inc. | Comments Off on Basta de que solo las empresas se beneficien de tus datos, ‘mydatamood’ quiere equilibrar la balanza a favor de los usuarios
Es algo obvio que los dispositivos extraíbles son un medio indispensable para el traspaso de información de forma rápida y sencilla, cargar nuevas configuraciones, actualizar el firmware de un dispositivo, etc. No obstante, si no tenemos una política rigurosa y llevamos a cabo buenas prácticas para su uso, pueden convertirse en una amenaza en vez de ayudar a prevenirlas. Por este motivo, debemos tener claro cuál es el rol de los USB dentro de SCI, sus ventajas mediante un uso correcto y mejorar sus puntos más débiles para evitar riesgos innecesarios.
Utilización de dispositivos USB en SCI y amenazas por un uso inseguro
Los dispositivos USB extraíbles y las unidades de memoria flash, son muy utilizados en el día a día dentro de los Sistemas de Control, por ese motivo tenemos que tener especial cuidado, ya que son uno de los principales vectores de amenaza en el ámbito de la ciberseguridad. El conflicto surge debido a que las redes industriales son bastante complejas y, además, solemos encontrar gran cantidad de dispositivos que no se encuentran conectados a la red por cuestiones de seguridad, por lo que una de las formas más habituales de acceder a ellos es mediante USB.
Estos medios extraíbles son una forma de simplificar este procedimiento, pero a su vez, conlleva el riesgo de introducir algún malware en estos sistemas o la posibilidad de que sea un BadUSB. Por otra parte, tener una gran variedad de dispositivos de campo hace complicado, sino imposible, la gestión a todos desde una misma aplicación, y se requiere en general el uso de USB para tratar con ellos. También se debe hacer hincapié en que la vida útil de los equipos suele ser bastante larga y se combinan sistemas heredados. Por supuesto, la mayor amenaza que tienen los USB es el personal que maneja los dispositivos de control, ya que son ellos los encargados de manipular estas memorias.
Incidentes provocados por dispositivos USB
Los dispositivos USB son uno de los riesgos o amenazas para SCI más grandes desde hace mucho tiempo. Una determinada cantidad del malware detectado en este entorno ha entrado por vía USB, ya que no se hizo uso de buenas prácticas. Algunos de los incidentes provocados, más conocidos, cuyo vector de ataque fue a través de estos dispositivos, son STUXNET y TRITON.
En general la mayoría del malware que se introduce mediante estos dispositivos suelen ser troyanos, aunque no es el único tipo que nos podemos encontrar. Dentro de los troyanos tenemos varios subtipos como “backdoor”, “bots”, “Droppers”, etc. Otros tipos podrían ser “Adware”, “Rootkits” y gusanos. Todos ellos, son malware que infectan los dispositivos e intentan permanecer ocultos al usuario y de esta forma, obtener información para algún proceso o ejecutar código de manera remota.
Por otra parte, estos dispositivos consiguieron desbaratar la medida de seguridad conocida como Air GAP, consistente en aislar la red deseada para protegerla de manera más eficiente de redes que pudieran ser una amenaza. El problema reside al conectar el USB que contiene el malware a la red que tenemos protegida mediante este aislamiento, ya que esta barrera de seguridad queda totalmente inservible. De esta forma, un atacante podría infectar mediante comandos los dispositivos que vea necesarios. Después de esto, solo tendría que sacar la información obtenida de esta red para que el ataque sea totalmente satisfactorio. Por esta razón, es necesario mejorar el uso de dispositivos USB de manera segura.
Uso seguro de USB
La seguridad de los USB debería incluir controles técnicos y normativos, ya que confiar solo en las actualizaciones no será suficiente para prevenir posibles amenazas.
Aunque está muy generalizado pensar que estos dispositivos son peligrosos y que, en gran medida, van acompañados de algún malware, actualmente sin estos dispositivos no podría ser factible la funcionalidad de las plantas. Por esta razón, si se toman precauciones y se hace un buen uso de ellos, representan un complemento muy útil en el entorno industrial.
Además de contar con una política interna para la utilización de dispositivos USB, hay que implantar buenas prácticas que nos ayudarán a minimizar el riesgo de infección en nuestro entorno:
Usar siempre USB corporativos que estén debidamente protegidos y con las medidas de seguridad adecuadas, almacenándolos en lugares apropiados, e informar al departamento responsable si hubiese algún incidente.
Controlar los dispositivos externos utilizados dentro de la empresa mediante un inventariado, que incluya un identificador inequívoco para cada uno.
No usar dispositivos personales para almacenar información referente a la empresa, en la medida de lo posible. Y si fuese necesario su uso, hacerlo teniendo la autorización de un superior o técnico, cumpliendo las políticas internas referentes al mismo, que debería incluir como mínimo un formateo, cifrado, borrado seguro de los datos y el escaneo previo.
Siempre que sea posible, usar los dispositivos en un entorno de prueba para verificar que no contengan ninguna amenaza.
Análisis frecuentes de los medios extraíbles mediante antivirus, por prevención.
Borrado seguro de la información confidencial, asegurándonos de que nadie podrá recuperar esos datos.
Seguridad de puertos USB inmediata y personalizada para redes industriales, obteniendo una mejora en la seguridad y reduciendo la infección de malware u otras amenazas.
Actualizaciones de seguridad en curso y continuas para los USB.
Mejor visibilidad de la utilización de USB y actividad de amenazas mediante el control de riesgos que podemos obtener, si seguimos una buena política de seguridad.
Formación en el uso correcto de este tipo de dispositivos en las empresas a todos los empleados para que sean conscientes de las posibles amenazas, fomentar así el uso seguro y responsable y evitar los riesgos innecesarios.
Nunca usar dispositivos de origen desconocidos que se hayan encontrado fuera o dentro de la zona de trabajo.
Indispensable la utilización de una herramienta, de la cual hablaremos a continuación, que permita la prevención de riesgos para los USB antes de acceder a las instalaciones.
Kioskos, medida de prevención
Las instalaciones industriales requieren un medio seguro para que no haya infección malware mediante USB o medios extraíbles similares.
Los kioscos son dispositivos que se están empezando a desplegar en el ámbito industrial por su eficacia, al asegurar que los dispositivos extraíbles no tengan ninguna amenaza en su interior. Pueden proporcionar una protección más avanzada para verificar el estado de estos dispositivos extraíbles mediante su funcionamiento. Algunas de sus funcionalidades incluyen:
Contención de amenazas mediante blacklist, análisis simultáneos mediante múltiples motores de antivirus.
Protección ante BadUSB. Control de dispositivos USB con firmware firmado, bastionado de kioscos, control e inventario de USB, además de control de ordenadores finales.
Opción para múltiples dispositivos externos, además de USB.
Análisis de los certificados de los ficheros firmados.
Opción de un borrado seguro. Se eliminan los datos contenidos en el USB de forma definitiva, sin la posibilidad de poder recuperarlos.
Control de uso de kioscos. Se autoriza quién puede usarlos para analizar los dispositivos y llevar un registro de ellos.
Mejoramos la seguridad de la planta donde se instala el kiosco al poder combinar su análisis USB con las actualizaciones basadas en la nube para posibles amenazas.
Al habilitar diferentes puestos de kioscos, se podrá reducir el riesgo de explotación malware al tener monitorizados y controlados los dispositivos extraíbles en todas las áreas donde sea necesario su despliegue.
Control físico e inventariado de dispositivos USB, así como impresión de tickets de autorización para los dispositivos analizados.
Conclusiones
Aunque es cierto que los tipos de amenazas provocadas por medios USB han sido más serias de lo que se pensaba inicialmente, es inevitable que siga habiendo exposición a amenazas para los dispositivos vía USB. Sin embargo, con una política correcta y el seguimiento de unas buenas prácticas de uso de estos dispositivos, se podrá reducir la mayoría de los peligros.
Por otro lado, la utilización de kioscos, una herramienta que se está empezando a implementar cada vez más en la industria, gracias al control de amenazas que proporciona, nos dará una mejor eficacia para el trabajo con USB.
Como siempre la formación, concienciación, prevención y la utilización segura de estos son la clave para evitar un incidente de seguridad debido a un mal uso de los dispositivos.
Aunque se haga un buen uso de este medio, lo mejor siempre será combinar varias medidas de seguridad para que la eficiencia sea más alta. Por este motivo, no tenemos que olvidarnos de otras medidas como la monitorización, el control de zonas y conductos o la gestión de parches, ya que un uso adecuado de todos estos conceptos hará que los Sistemas de Control tengan menos riesgos.
Windows 10 recibió un par de actualizaciones acumulativas tanto para la Fall Creators Update, como para la April 2018 Update. Esas son las dos últimas versiones oficiales del sistema de Microsoft, y es importante instalarlas para deja tu sistema a punto ya sea que quieras o no quieras actualizar a la nueva versión de octubre.
Este 2 de octubre tenemos evento de Surface y los rumores apuntan a que ese mismo día se lanzará la próxima gran actualización de Windows 10. Teniendo en cuenta que los problemas post actualización no son precisamente raros con Windows, es buena idea descargar una imagen oficial de la versión estable actual, en caso de emergencia y mientras puedas.
Si bien, Windows 10 te ofrece la opción de regresar a una compilación anterioren caso de que algo vaya mal con la actualización, a veces hay quien tiene la mala suerte que ni esa opción le funciona. De ahí que tener una imagen de la última versión que te iba bien, no sea mala idea. Especialmente si quieres una instalación completamente limpia.
Windows 10 1803 es la actualización de abril 2018, la que esperamos para octubre es la versión 1809. En estos momentos, mientras aún tenemos la de abril como la versión actual, es posible descargar el ISO oficial de Windows 10 usando la misma herramienta de Microsoft que se nos ofrece para actualizar.
Lo primero que necesitas hacer es ir a la web oficial de Microsoft para descargar Windows 10. Debes hacerlo desde un ordenador con Windows, y debes tener al menos unos 8 GB de espacio disponibles para guardar la imagen.
Haz click en Descargar ahora la herramienta y elige un sitio para guardar el programa MediaCreationTool1803.exe. Ejecuta la herramienta que acabas de descargar haciendo doble click sobre el archivo.
Espera que el programa termine de hacer preparativos y acepta los términos para poder continuar. Cuando se presente la pregunta “¿Qué deseas hacer?”, selecciona Crear medios de instalación y presiona “siguiente”.
Elige idioma, edición y arquitectura (usualmente basta con dejar lo que viene por defecto) y presiona “siguiente”.
En la siguiente pantalla tienes la opción de elegir una unidad USB y crear de una vez tu disco de arranque, o elegir “Archivo ISO”. Ese archivo ISO lo puedes guardar donde quieras y montar tu imagen luego desde cualquier sistema.
Selecciona “Archivo ISO” y presiona “siguiente”. Elige la carpeta donde lo quieres guardar y listo. Solo tienes que esperar que finalice la descarga. Ignora todo lo que tiene que ver con el DVD, ese ISO lo puedes montar perfectamente en un USB en el futuro.
Existen herramientas aparte de la de Windows para crear discos de arranque USBque puedes usar en cualquier otro sistema operativo. Además, recuerda la razón por la que estamos guardando este ISO, en caso de emergencia, no lo guardes en el ordenador que vas a actualizar, al menos no en la misma partición que el Windows 10 que vas a actualizar.
Es importante que si quieres esta versión la descargues antes de la primera semana de octubre, salvo que la próxima actualización se retrase, el ISO que se baja con esta herramienta será cambiado por el de Windows 10 1809 tan pronto como se libere la actualización.
Posted by MuSsUtO JoRgE® |
September 28, 2018 | Categories: Systems Computers U.S.A. Inc. | Comments Off on Como descargar un ISO oficial de Windows 10 antes de la actualización de octubre, en caso de emergencia
Digital transformation is an omnipresent topic today, providing a lot of challenges as well as chances. Due to that, customers are asking about how to deal with those challenges and how to leverage from the provided chances. Frequently asked questions in this area are:
How can we modernize existing applications?
What are the key elements for a future-proven strategy IT system architecture?
How can the flexibility as well as the agility of the IT system landscape be ensured?
But from our experience there’s no common answer for these questions, since every customer has individual requirements and businesses, but it is necessary to find pragmatic solutions, which leverage from existing best Practices – it is not necessary to completely re-invent the wheel.
With our new poster „Four Pillars of Digitalization based on Oracle Cloud“ (Download it here) , we try to deliver a set of harmonized reference models which we evolved based on our practical experience, while conceiving modern, future-oriented solutions in the area of modern application designs, integrative architectures, modern infrastructure solutions and analytical architectures. The guiding principle, which is the basis for our architectural thoughts is: Design for Change. If you want to learn more, you can refer to our corresponding Ebook (find the Ebook here, only available in German at the moment).
Usually the technological base for modern application architectures today is based on Cloud services, where the offerings of different vendors are constantly growing. Here it is important to know which Cloud services are the right ones to implement a specific use case. Our poster „Four Pillars of Digitalization based on Oracle Cloud“ shows the respective Cloud services of our strategic partner Oracle, which can be used to address specific challenges in the area of digitalization. Get the poster here.
Thank you all who tuned in for my first of four “ECM by the Decades” radio shows on WKCR. Host Andrew Castillo and I will continue our saga through the label on March 12, March 26, and April 9. For those of you who joined us live during the first show, you will be pleased to know that the station’s fundraising efforts for this cycle are complete and that our show will no longer be interrupted. I am grateful for your patience the first time around. We’ll be on the air next Monday from 6-9pm EST, streamling live on the station website here. A podcast version will also appear on this website soon thereafter.
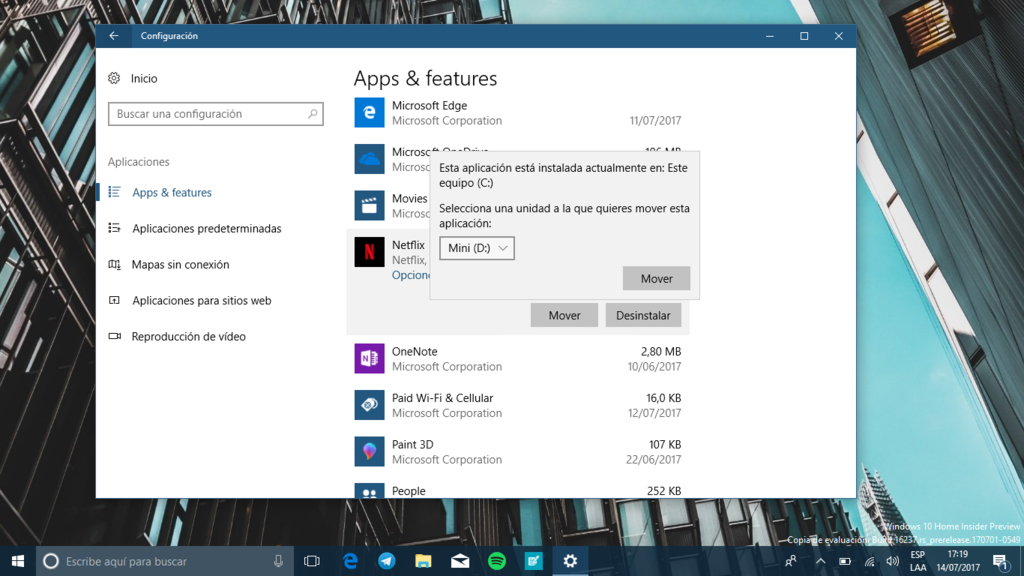
Ahora, si tienes uno de esos ordenadores que traen una cantidad de espacio bastante limitada, vas a querer ahorrar hasta en lo más insignificante, como una app de menos de 100 MB. Por suerte Windows 10 no solo te deja mover apps a un almacenemiento externo, sino que te permite establecer otro disco como la ubicación por defecto para instalar tus aplicaciones.
Puedes usar un pendrive, una tarjeta SD, o un disco duro externo. No importa el medio realmente, lo único que importa es que lo mantengas conectado al ordenador y lo formatees como NTFS.
Primero conecta la unidad de almacenamiento a tu ordenador, luego navega a Este Equipo y selecciona el dispositivo que conectaste de la lista. Haz click derecho sobre la unidad y luego en Formatear… (ten en cuenta que esto borra todos los datos de la unidad).
En Sistema de archivos selecciona NTFS en el menú desplegable. Si quieres puedes darle un nombre a la unidad en el cuadro Etiqueta del volumen. Luego presiona Iniciar y espera que termine. Estás listo para usar la unidad.
Mover aplicaciones de Windows 10 a otra unidad
No todas las aplicaciones pueden ser movidas a otra unidad, tendrás que revisar una por una las que quieras mover. Para ello abre el menú de Configuración presionando la tecla de Windows + I y selecciona Aplicaciones.
Navega por la lista de aplicaciones y selecciona la que te interese mover. Si el botón funciona, simplemente haz click en él y luego presiona aplicar para mover la aplicación a la nueva unidad. Repite con las que quieras, una a una, lamentablemente no se puede hacer por lote.
Si quieres que todas las apps que instales en el futuro se guarden en el dispositivo de almacenamiento externo, también puedes hacerlo.
Abre el menú de configuración nuevamente y ve a Sistema. En el menú de la derecha selecciona Almacenamiento. Ahí busca la opción Cambiar la ubicación de almacenamiento del contenido nuevo y haz click sobre ella.
Ahora puedes elegir otra unidad para guardar las aplicaciones nuevas. También puedes hacer lo mismo con otro tipo de contenido, documentos, música, fotos, vídeos, etc.
Windows Defender es un antivirus bastante bueno, es una herramienta sólida y que al venir ya integrada en Windows tiene un impacto muy bajo en el rendimiento del sistema en comparación son soluciones de terceros. No decimos que sea perfecto, pero como solución de seguridad básica, gratuita e integrada perfectamente con Windows 10, queda muy bien parada.
Con la llegada de la Creators Update Microsoft le dio un lavado de cara a su herramienta antivirus y lo ha convertido en un Centro de seguridad completo con varias opciones para protegerte de diferentes amenazas o solucionar problemas en un par de clicks.
Una de las características más importantes de Windows Defender es la protección basada en la nube, ya que esta dice proporcionar mayor protección y de forma más rápida al tener acceso a los datos más recientes. Y con la Creators Update también puedes elegir manualmente el nivel de protección basada en la nube y aumentarlo, solo que el proceso es algo más complicado que marcar una casilla en el Centro de seguridad.
Requisitos
Es importante que sepas algunas cosas antes de comenzar. La primera es que para poder aumentar el nivel de protección de Windows Defender necesitarás editar el registro de Windows y tendrás que unirte al programa MAPS de Microsoft.
Al unirte al programa MAPS de Microsoft aceptarás que la empresa recopile varias piezas de información sobre las amenazas detectadas en tu equipo, y en algún momento quizás se recopile tu información personal, aunque Microsoft promete que no la usará para identificarte o contactarte.
Antes de proceder a editar el registro de Windows es importante que tengas cuidado en hacerlo de forma correcta o podrías dañar tu sistema de forma permanente. Te recomendamos crear un punto de restauración al que puedas volver en caso de que algo vaya mal.
Cambiar el nivel de protección en la nube de Windows Defender
Presiona la tecla de Windows + R y escribe “regedit” (sin las comillas) y presiona Enter. Esto abrirá el Editor del Registro de Windows.
Navega hasta la siguiente ruta:
Selecciona Nuevo, luego elige Clave, nombra la nueva carpeta Spynet y presiona Enter:
Ahora haz click derecho en Spynet, elige Nuevo, luego selecciona Valor de DWORD (32 bits) y cambia el nombre a SpynetReporting. Presiona Enter. Luego haz doble click en SpynetReporting y cambia la Información del valor de 0 a 2. Presiona Aceptar.
Con esto te habrás unido al programa de Microsoft MAPS. Ahora es momento de cambiar el nivel de protección antivirus basado en la nube.
Vuelve a abrir el editor del registro, navega hasta la misma ruta:
Haz click derecho sobre la carpeta Windows Defender, selecciona Nuevo y luego haz click en Clave. Nombra la nueva carpeta como MpEngine y presiona Enter.
Ahora haz click derecho sobre MpEngine, selecciona Nuevo y luego elige Valor de DWORD (32 bits). Cambia el nombre de la clave a MpCloudBlockLevel y presiona Enter. Haz doble click sobre MpCloudBlockLevel y cambia el número en información del valor de 0 a 2 y presiona Aceptar.
Una vez completados estos pasos, Windows Defender usará un nivel de protección más elevado a la hora de escanear y detectar archivos sospechosos en tu ordenador. Esperemos que estas opciones aparezcan tarde o temprano directamente en el Centro de seguridad para no tener que recurrir a editar el registro si queremos disfrutar de ellas.
Gerrymandering is the practice of manipulating boundaries in such a way that favors a political party. If you slice and group in various ways, you can end up with different election results.
How many different ways can you draw boundaries though? And can results really change that much, depending on you draw the boundaries? District, by Christopher Walker, is a puzzle game that shows you how it works. The goal: Group circles in such a way that favors your color.
An anonymous reader writes: The audio driver installed on some HP laptops includes a feature that could best be described as a keylogger, which records all the user’s keystrokes and saves the information to a local file, accessible to anyone or any third-party software or malware that knows where to look. Swiss cyber-security firm modzero discovered the keylogger on April 28 and made its findings public today. According to researchers, the keylogger feature was discovered in the Conexant HD Audio Driver Package version 1.0.0.46 and earlier. This is an audio driver that is preinstalled on HP laptops. One of the files of this audio driver is MicTray64.exe (C:\windows\system32\mictray64.exe). This file is registered to start via a Scheduled Task every time the user logs into his computer. According to modzero researchers, the file “monitors all keystrokes made by the user to capture and react to functions such as microphone mute/unmute keys/hotkeys.”







































 Gerrymandering is the practice of manipulating boundaries in such a way that favors a political party. If you slice and group in various ways, you can end up with different election results.
Gerrymandering is the practice of manipulating boundaries in such a way that favors a political party. If you slice and group in various ways, you can end up with different election results.



