
Hardening Windows 10 with zero-day exploit mitigations
A key takeaway from the detonation of zero-day exploits is that each instance represents a valuable opportunity to assess how resilient a platform can be—how mitigation techniques and additional defensive layers can keep cyberattacks at bay while vulnerabilities are being fixed and patches are being deployed. Because it takes time to hunt for vulnerabilities and it is virtually impossible to find all of them, such security enhancements can be critical in preventing attacks based on zero-day exploits.
In this blog, we look at two recent kernel-level zero-day exploits used by multiple activity groups. These kernel-level exploits, based on CVE-2016-7255 and CVE-2016-7256 vulnerabilities, both result in elevation of privileges. Microsoft has promptly fixed the mentioned vulnerabilities in November 2016. However, we are testing the exploits against mitigation techniques delivered in August 2016 with Windows 10 Anniversary Update, hoping to see how these techniques might fare against future zero-day exploits with similar characteristics.
| CVE | Microsoft Update | Exploit Type | Mitigation in Anniversary Update |
| CVE-2016-7255 | MS16-135 (Nov, 2016) | Win32k Elevation of Privilege Exploit | Strong validation of tagWND structure |
| CVE-2016-7256 | MS16-132 (Nov, 2016) | Open Type Font Exploit | Isolated Font Parsing (AppContainer) Stronger validation in font parsing |
CVE-2016-7255 exploit: Win32k elevation of privilege
In October 2016, the STRONTIUM attack group launched a spear-phishing campaign targeting a small number of think tanks and nongovernmental organizations in the United States. The campaign, also discussed in the previously mentioned blog post, involved the use of the exploit for CVE-2016-7255 in tandem with an exploit for the Adobe Flash Player vulnerability CVE-2016-7855.
The attack group used the Flash exploit to take advantage of a use-after-free vulnerability and access targeted computers. They then leveraged the type-confusion vulnerability in win32k.sys (CVE-2016-7255) to gain elevated privileges.
Abusing the tagWND.strName kernel structure
In this section, we’ll go through the internals of the specific exploit for CVE-2016-7255 crafted by the attacker. We will show how mitigation techniques provided customers with preemptive protection from the exploit, even before the release of the specific update fixing the vulnerability.

Figure 1. Exploit and shellcode phases of this attack
Modern exploits often rely on read-write (RW) primitives to achieve code execution or gain additional privileges. For this exploit, attackers acquire RW primitives by corrupting tagWND.strName kernel structure. This exploit method is a trend discussed in security conferences and visible to those who investigated actual attacks. For example, we detailed similar findings in a presentation about the Duqu 2.0 exploit at Virus Bulletin 2015.
By reverse engineering its code, we found that the Win32k exploit used by STRONTIUM in October 2016 reused the exact same method. The exploit, after the initial Win32k vulnerability, corrupts tagWND.strName structure and uses SetWindowTextW to write arbitrary content anywhere in kernel memory.

Figure 2. SetWindowTextW as a write primitive
The exploit abuses this API call to overwrite data of current processes and copy token privileges of the SYSTEM. If successful, the exploit enables the victim process—iexplore.exe, in this example—to execute with elevated privileges.
Figure 3. Internet Explorer with SYSTEM privileges
Mitigating tagWND exploits with stronger validation
To mitigate the Win32k exploit and similar exploits, the Windows Offensive Security Research Team (OSR) introduced techniques in the Windows 10 Anniversary Update that prevent abusive use of tagWND.strName. This mitigation performs additional checks for the base and length fields, making sure that they are in the expected virtual address ranges and are not usable for RW primitives. In our tests on Anniversary Update, exploits using this method to create an RW primitive in the kernel are ineffective. These exploits instead cause exceptions and subsequent blue screen errors.

Figure 4. Windows 10 Anniversary Update mitigation on a common kernel write primitive
With the upcoming Windows 10 Creators Update, Windows Defender ATPintroduces numerous forms of generic kernel exploit detection for deeper visibility into targeted attacks leveraging zero-day exploits. Technical details about the enhanced sensor will be shared in a forthcoming blog post.
CVE-2016-7256 exploit: Open type font elevation of privilege
As early as June 2016, unidentified actors began to use an implant detected as “Henkray” in low-volume attacks primarily focused on targets in South Korea. Later, in November 2016, these attackers were detected exploiting a flaw in the Windows font library (CVE-2016-7256) to elevate privileges and install the Henkray backdoor on targeted computers with older versions of Windows.
The font samples found on affected computers were specifically manipulated with hardcoded addresses and data to reflect actual kernel memory layouts. This indicates the likelihood that a secondary tool dynamically generated the exploit code at the time of infiltration.

Figure 5. Auto-generation of font file with exploit
This secondary executable or script tool, which has not been recovered, appears to prepare and drop the font exploit, calculating and preparing the hardcoded offsets needed to exploit the kernel API and the kernel structures on the targeted system. Through deep forensic inspection of the binary data found in samples, we extracted all the hardcoded offsets and ascertained the kernel version targeted by this exploit: Windows 8 64-bit.
Function table corruption for initial code execution
The font exploit uses fa_Callbacks to corrupt the function table and achieve initial code execution. The callback is called from the CFF parsing function. The following snippet shows a corrupted ftell pointer to a nt!qsort+0x39 location in kernel code.

Figure 6. fa_Callbacks table corruption
The following snippet shows the code that calls the corrupt function pointer leading to a kernel ROP chain.
Figure 7. fa_Callbacks.ftell function call code
When the corrupted function is called, the control jumps to the first ROP gadget at nt!qsort+0x39, which adjusts stack pointer and initializes some register values from stack values.

Figure 8. First ROP gadget
After the first gadget, the stack points to a kernel ROP chain which calls to ExAllocatePoolWithTag call to reserve shellcode memory. Another ROP gadget will copy the first 8 bytes of the stage 1 shellcode to the allocated memory.

Figure 9. Copying the stage 1 shellcode
Shellcode and privilege escalation
The stage 1 shellcode is very small. Its main function is to copy the main body of the shellcode to newly allocated memory and run them with a JMP RAX control transfer.

Figure 10. Stage 1 shellcode
The main shellcode runs after the copy instructions. The main shellcode—also a small piece of code—performs a well-known token-stealing technique. It then copies the token pointer from a SYSTEM process to the target process, achieving privilege escalation. Both the SYSTEM process and target process PIDs, as well as certain offsets for the kernel APIs needed by the shellcode, are hardcoded in the font sample.

Figure 11. Token replacement technique
Mitigating font exploits with AppContainer
When opening the malicious font sample on Windows 10 Anniversary Update, font parsing happens completely in AppContainer instead of the kernel. AppContainer provides an isolated sandbox that effectively prevents font exploits (among other types of exploits) from gaining escalated privileges. The isolated sandbox considerably reduces font parsing as an attack surface.

Figure 12. AppContainer protects against untrusted fonts in Windows 10 Anniversary Update
Windows 10 Anniversary Update also includes additional validation for font file parsing. In our tests, the specific exploit code for CVE-2016-7256 simply fails these checks and is unable to reach vulnerable code.

Figure 13. Windows 10 font viewer error
Conclusion: Fighting the good fight with exploit mitigation and layered detection
While fixing a single-point vulnerability helps neutralize a specific bug, Microsoft security teams continue to look into opportunities to introduce more and more mitigation techniques. Such mitigation techniques can break exploit methods, providing a medium-term tactical benefit, or close entire classes of vulnerabilities for long-term strategic impact.
In this article, we looked into recent attack campaigns involving two zero-day kernel exploits. We saw how exploit mitigation techniques in Windows 10 Anniversary Update, which was released months before these zero-day attacks, managed to neutralize not only the specific exploits but also their exploit methods. As a result, these mitigation techniques are significantly reducing attack surfaces that would have been available to future zero-day exploits.
By delivering these mitigation techniques, we are increasing the cost of exploit development, forcing attackers to find ways around new defense layers. Even the simple tactical mitigation against popular RW primitives forces the exploit authors to spend more time and resources in finding new attack routes. By moving font parsing code to an isolated container, we significantly reduce the likelihood that font bugs are used as vectors for privilege escalation.
In addition to the techniques mentioned in this article, Windows 10 Anniversary Update introduced many other mitigation techniques in core Windows components and the Microsoft Edge browser, helping protect customers from entire classes of exploits for very recent and even undisclosed vulnerabilities.
For effective post-breach detection, including cover for the multiple stages of attacks described in this blog post, sign up for Window Defender ATP. The service leverages built-in sensors to raise alerts for exploits and other attack activity, providing corresponding threat intelligence. Customers interested in the Windows Defender ATP post-breach detection solution can find more information here.
Microsoft would like to thank KrCERT for their collaboration in protecting customers and for providing the sample for CVE-2016-7256.
Matt Oh and Elia Florio, Windows Defender ATP Research Team
Updates:
Jan 18, 2017 – Corrected the spelling of Henkray backdoor.
Should Banks Let Ancient Programming Language COBOL Die?
Read more of this story at Slashdot.
How Cybercrooks Put the Beatdown on My Beats
Krebs on Security
Last month Yours Truly got snookered by a too-good-to-be-true online scam in which some dirtball hijacked an Amazon merchant’s account and used it to pimp steeply discounted electronics that he never intended to sell. Amazon refunded my money, and the legitimate seller never did figure out how his account was hacked. But such attacks are becoming more prevalent of late as crooks increasingly turn to online crimeware services that make it a cakewalk to cash out stolen passwords.

The item at Amazon that drew me to this should-have-known-better bargain was a Sonoswireless speaker that is very pricey and as a consequence has hung on my wish list for quite some time. Then I noticed an established seller with great feedback on Amazon was advertising a “new” model of the same speaker for 32 percent off. So on March 4, I purchased it straight away — paying for it with my credit card via Amazon’s one-click checkout.
A day later I received a nice notice from the seller stating that the item had shipped. Even Amazon’s site seemed to be fooled because for several days Amazon’s package tracking system updated its progress slider bar steadily from left to right.
Suddenly the package seemed to stall, as did any updates about where it was or when it might arrive. This went on for almost a week. On March 10, I received an email from the legitimate owner of the seller’s account stating that his account had been hacked.
Identifying myself as a reporter, I asked the seller to tell me what he knew about how it all went down. He agreed to talk if I left his name out of it.
“Our seller’s account email address was changed,” he wrote. “One night everything was fine and the next morning our seller account had a email address not associated with us. We could not access our account for a week. Fake electronic products were added to our storefront.”
He couldn’t quite explain the fake tracking number claim, but nevertheless the tactic does seem to be part of an overall effort to delay suspicion on the part of the buyer while the crook seeks to maximize the number of scam sales in a short period of time.
“The hacker then indicated they were shipped with fake tracking numbers on both the fake products they added and the products we actually sell,” the seller wrote. “They were only looking to get funds through Amazon. We are working with Amazon to refund all money that were spent buying these false products.”
As these things go, the entire ordeal wasn’t awful — aside maybe from the six days spent in great anticipation of audiophilic nirvana (alas, after my refund I thought better of the purchase and put the item back on my wish list.) But apparently I was in plenty of good (or bad?) company.
The Wall Street Journal notes that in recent weeks “attackers have changed the bank-deposit information on Amazon accounts of active sellers to steal tens of thousands of dollars from each, according to several sellers and advisers. Attackers also have hacked into the Amazon accounts of sellers who haven’t used them recently to post nonexistent merchandise for sale at steep discounts in an attempt to pocket the cash.”
Perhaps fraudsters are becoming more brazen of late with hacked Amazon accounts, but the same scams mentioned above happen every day on plenty of other large merchandising sites. The sad reality is that hacked Amazon seller accounts have been available for years at underground shops for about half the price of a coffee at Starbucks.
The majority of this commerce is made possible by one or two large account credential vendors in the cybercrime underground, and these vendors have been collecting, vetting and reselling hacked account credentials at major e-commerce sites for years.
I have no idea where the thieves got the credentials for the guy whose account was used to fake sell the Sonos speaker. But it’s likely to have been from a site like SLILPP, a crime shop which specializes in selling hacked Amazon accounts. Currently, the site advertises more than 340,000 Amazon account usernames and passwords for sale.
The price is about USD $2.50 per credential pair. Buyer scan select accounts by balance, country, associated credit/debit card type, card expiration date and last order date. Account credentials that also include the password to the victim’s associated email inbox can double the price.
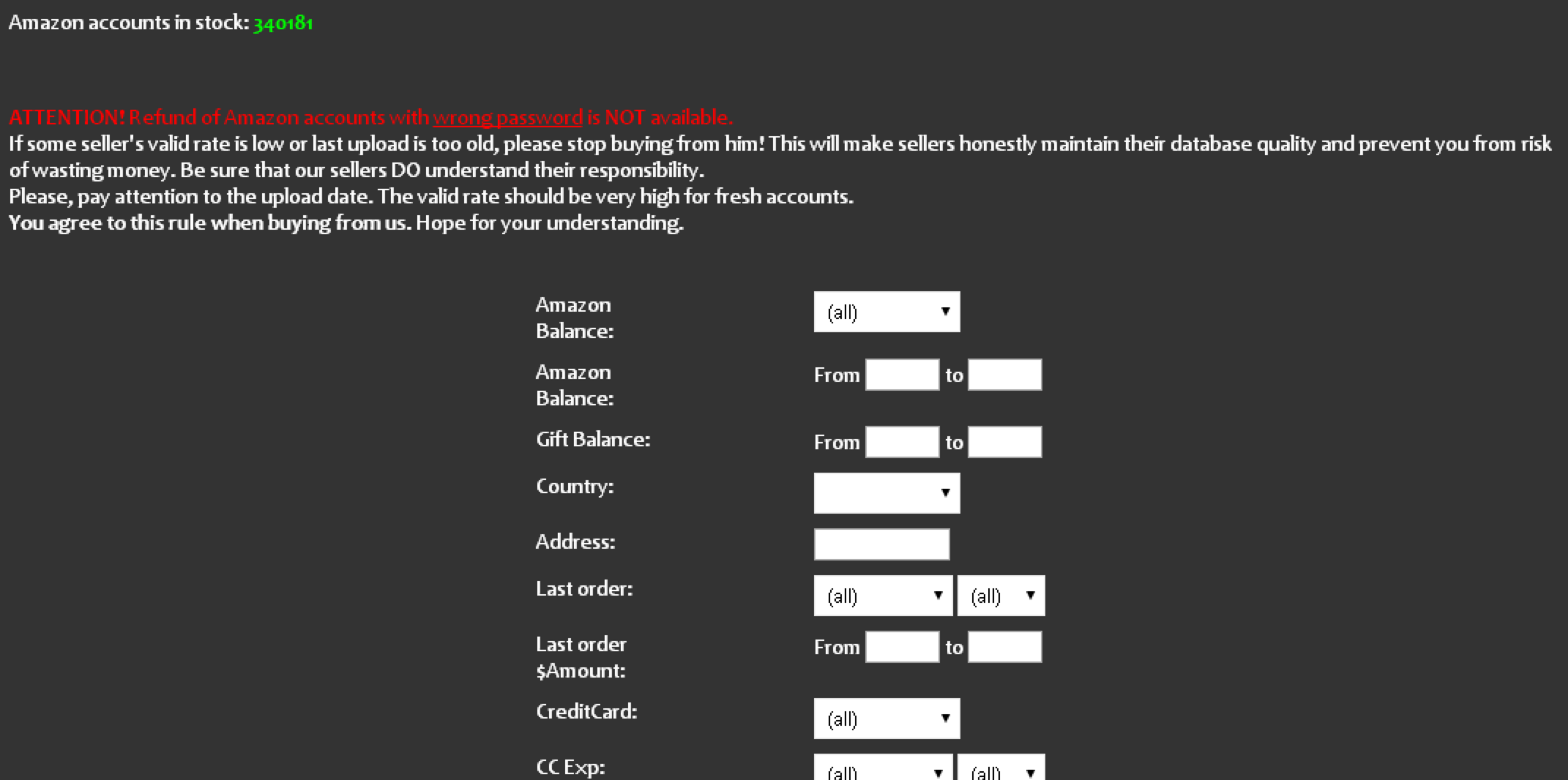
If memory serves correctly, SLILPP started off years ago mainly as a PayPal and eBay accounts seller (hence the “PP”). “Slil” is transliterated Russian for “слил,” which in this context may mean “leaked,” as in password data that has leaked from other now public breaches. SLILPP has vastly expanded his store in the years since: It currently advertises more than 7.1 million credentials for sale from hundreds of popular bank and e-commerce sites.
The site’s proprietor has been at this game so long he probably deserves a story of his own soon, but for now I’ll say only that he seems to do a brisk business buying up credentials being gathered by credential-testing crime crews — cyber thieves who spend a great deal of time harvesting and enriching credentials stolen and/or leaked from major data breaches at social networking and e-commerce providers in recent years.

Fraudsters can take a list of credentials stolen from, say, the Myspace.com breach (in which some 427 million credentials were posted online) and see how many of those email address and password pairs from the MySpace accounts also work at hundreds of other bank and e-commerce sites.
Password thieves often then turn to crimeware-as-a-service tools like Sentry MBA, which can vastly simplify the process of checking a list of account credentials at multiple sites. To make blocking their password-checking activities more challenging for retailers and banks to identify and block, these thieves often try to route the Internet traffic from their password-guessing tools through legions of open Web proxies, hacked PCs or even stolen/carded cloud computing instances.
PASSWORD RE-USE: THE ENGINE OF ALL ONLINE FRAUD
In response, many major retailers are being forced to alert customers when they see known account credential testing activity that results in a successful login (thus suggesting the user’s account credentials were replicated and compromised elsewhere). However, from the customer’s perspective, this is tantamount to the e-commerce provider experiencing a breach even though the user’s penchant for recycling their password across multiple sites is invariably the culprit.
There are a multitude of useful security lessons here, some of which bear repeating because their lack of general observance is the cause of most password woes today (aside from the fact that so many places still rely on passwords and stupid things like “secret questions” in the first place). First and foremost: Do not re-use the same password across multiple sites. Secondly, but equally important: Never re-use your email password anywhere else.
Also, with a few exceptions, password length is generally more important than password complexity, and complex passwords are difficult to remember anyway. I prefer to think in terms of “pass phrases,” which are more like sentences or verses that are easy to remember.
If you have difficult recalling even unique passphrases, a password manager can help you pick and remember strong, unique passwords for each site you interact with, requiring only one strong master password to unlock any of them. Oh, and if the online account in question allows 2-factor authentication, be sure to take advantage of that.
I hope it’s clear that Amazon is just one of the many platforms where fraudsters lurk. SLILPP currently is selling stolen credentials for nearly 500 other banks and e-commerce sites. The full list of merchants targeted by this particularly bustling fraud shop is here (.txt file).
As for the “buyer beware” aspect of this tale, in retrospect there were several warning signs that I either ignored or neglected to assign much weight. For starters, the deal that snookered me was for a luxury product on sale for 32 percent off without much explanation as to why the apparently otherwise pristine item was so steeply discounted.
Also, while the seller had a stellar history of selling products on Amazon for many years (with overwhelmingly positive feedback on virtually all of his transactions) he did not have a history of selling the type of product that thieves tried to sell through his account. The old adage “If something seems too good to be true, it probably is,” ages really well in cyberspace.
Undo Understood
Oracle Scratchpad
It’s hard to understand all the ramifications of Oracle’s undo handling, and it’s not hard to find cases where the resulting effects are very confusing. In a recent post on the OTN database forum resulted in one response insisting that the OP was obviously updating a table with frequent commits from one session while querying it from another thereby generating a large number of undo reads in the querying session.
It’s a possible cause of the symptoms that had been described – although not the only possible cause, especially since the symptoms hadn’t been described completely. It’s actually possible to see this type of activity when there are no updates and no outstanding commits taking place at all on the target table. Unfortunately it’s quite hard to demonstrate this with a quick, simple, script in recent versions of Oracle unless you do some insanely stupid things to make the problem appear – but I know how to do “insanely stupid” in Oracle, so here we go; first some data creation:
rem
rem Script: undo_rec_apply_2.sql
rem Author: Jonathan Lewis
rem Dated: March 2017
rem
create table t2(v1 varchar2(100));
insert into t2 values(rpad('x',100));
commit;
create table t1
nologging
pctfree 99 pctused 1
as
with generator as (
select
rownum id
from dual
connect by
level <= 1e4
)
select
cast(rownum as number(8,0)) id,
cast(lpad(rownum,10,'0') as varchar2(10)) v1,
cast(lpad('x',100,'x') as varchar2(100)) padding
from
generator v1,
generator v2
where
rownum <= 8e4 -- > comment to bypass WordPress formatting issue
;
alter table t1 add constraint t1_pk primary key(id)
;
begin
dbms_stats.gather_table_stats(
ownname => user,
tabname =>'T1',
method_opt => 'for all columns size 1'
);
end;
/
The t2 table is there as a target for a large of updates from a session other than the one demonstrating the problem. The t1 table has been defined and populated in a way that puts one row into each of 80,000 blocks (though, with ASSM and my specific tablespace definition of uniform 1MB extents, the total space is about 80,400 blocks). I’ve got a primary key declaration that allows me to pick single rows/blocks from the table if I want to.
At this point I’m going to do a lot of updates to the main table using a very inefficient strategy to emulate the type of thing that can happen on a very large table with lots of random updates and many indexes to maintain:
begin
for i in 1..800 loop
update t1 set v1 = upper(v1) where id = 100 * i;
execute immediate 'alter system switch logfile';
execute immediate 'alter system flush buffer_cache';
commit;
dbms_lock.sleep(0.01);
end loop;
end;
/
set transaction read only;
I’m updating every 100th row/block in the table with single row commits, but before each commit I’m switching log files and flushing the buffer cache.
This is NOT an experiment to try on a production system, or even a development system if there are lots of busy developers or testers around – and if you’re running your dev/test in archivelog mode (which, for some of your systems you should be) you’re going to end up with a lot of archived redo logs. I have to do this switch to ensure that the updated blocks are unpinned so that they will be written to disc and flushed from the cache by the flush buffer cache. (This extreme approach would not have been necessary in earlier versions of Oracle, but the clever developers at Oracle Corp. keep adding “damage limitation” touches to the code that I have to work around to create small tests.) Because the block has been flushed from memory before the commit the session will record a “commit cleanout failures: block lost” on each commit. By the time this loop has run to completion there will be 800 blocks from the table on disc needing a “delayed block cleanout”.
Despite the extreme brute force I use in this loop, there is a further very important detail that has to be set before this test will work (at least in 11.2.0.4, which is what I’ve used in my test runs). I had to start the database with the hidden parameter _db_cache_pre_warm set to false. If I don’t have the database started with this feature disabled Oracle would notice that the buffer cache had a lot of empty space and would “pre-warm” the cache by loading a few thousand blocks from t1 as I updated one row – with the side effect that the update from the previous cycle of the loop would be cleaned out on the current cycle of the loop. If you do run this experiment, remember to reset the parameter and restart the instance when you’ve finished.
I’ve finished this chunk of code with a call to “set transaction read only” – this emulates the start of a long-running query: it captures a point in time (through the current SCN) and any queries that run in the session from now on have to be read-consistent with that point in time. After doing this I need to use a second session to do a bit of hard work – in my case the following:
execute snap_rollstats.start_snap
begin
for i in 1..10000 loop
update t2 set v1 = upper(v1);
update t2 set v1 = lower(v1);
commit;
end loop;
end;
/
execute snap_rollstats.end_snap
The calls to the snap_rollstats package simply read v$rollstat and give me a report of the changes in the undo segment statistics over the period of the loop. I’ve executed 10,000 transactions in the interval, which was sufficient on my system to use each undo segment header at least 1,000 times and (since there are 34 transaction table slots in each undo segment header) overwrite each transaction table slot about 30 times. You can infer from these comments that I have only 10 undo segments active at the time, your system may have many more (check the number of rows in v$rollstat) so you may want to scale up that 10,000 loop count accordingly.
At this point, then, the only thing I’ve done since the start of my “long running query” is to update another table from another session. What happens when I do a simple count() from t1 that requires a full tablescan ?
alter system flush buffer_cache; execute snap_filestat.start_snap execute snap_my_stats.start_snap select count(v1) from t1; execute snap_my_stats.end_snap execute snap_filestat.end_snap
I’ve flushed the buffer cache to get rid of any buffered undo blocks – again an unreasonable thing to do in production but a valid way of emulating the aging out of undo blocks that would take place in a production system – and surrounded my count() with a couple of packaged call to report the session stats and file I/O stats due to my query. (If you’re sharing your database then the file I/O stats will be affected by the activity of other users, of course, but in my case I had a private database.)
Here are the file stats:
--------------
Datafile Stats
--------------
file# Reads Blocks Avg Size Avg Csecs S_Reads Avg Csecs M_Reads Avg Csecs Max Writes Blocks Avg Csecs Max
File name
----- ----- ------ -------- --------- ------- --------- ------- --------- --- ------ ------ --------- ---
1 17 17 1.000 .065 17 .065 0 .000 6 0 0 .000 15
/u01/app/oracle/oradata/TEST/datafile/o1_mf_system_938s4mr3_.dbf
3 665 665 1.000 .020 665 .020 0 .000 6 0 0 .000 15
/u01/app/oracle/oradata/TEST/datafile/o1_mf_undotbs1_938s5n46_.dbf
5 631 80,002 126.786 .000 2 .045 629 .000 6 0 0 .000 17
/u01/app/oracle/oradata/TEST/datafile/o1_mf_test_8k__cz1w7tz1_.dbf
As expected I’ve done a number of multiblock reads of my data tablespace for a total of roughly 80,000 blocks read. What you may not have expected is that I’ve done 665 single block reads of the undo tablespace.
What have I been doing with all those undo blocks ? Check the session stats:
Session stats ------------- Name Value ---- ----- transaction tables consistent reads - undo records applied 10,014 transaction tables consistent read rollbacks 10
We’ve been reading undo blocks so that we can create read-consistent copies of the 10 undo segment headers that were active in my instance. We haven’t (and you’ll have to trust me on this, I can’t show you the stats that aren’t there!) reported any “data blocks consistent reads – undo records applied”.
If you want to see a detailed explanation of what has happened you’ll need to read Oracle Core (UK source), chapter 3 (and possibly chapter 2 to warm yourself up for the topic). In outline the following type of thing happens:
- Oracle gets to the first block updated in t1 and sees that there’s an ITL (interested transaction list) entry that hasn’t been marked as committed (we flushed the block from memory before the commit cleanout could take place so the relevant transaction is, apparently, still running and the row is still marked as locked).
- Let’s say the ITL entry says the transaction was for undo segment 34, transaction table slot 11, sequence 999. Oracle reads the undo segment header block for undo segment 34 and checks transaction table slot 11, which is now at sequence 1032. Oracle can infer from this that the transaction that updated the table has committed – but can’t yet know whether it committed before or after the start of our “long running query”.
- Somehow Oracle has to get slot 11 back to sequence 999 so that it can check the commit SCN recorded in the slot at that sequence number. This is where we see “undo records applied” to make the “transaction table read consistent”. It can do this because the undo segment header has a “transaction control” section in it that records some details of the most recent transaction started in that segment. When a transaction starts it updates this information, but saves the old version of the transaction control and the previous version of its transaction table slot in its first undo record, consequently Oracle can clone the undo segment header block, identify the most recent transaction, find its first undo record and apply it to unwind the transaction table information. As it does so it has also wound the transaction control section backwards one step, so it can use that (older) version to go back another step … and so on, until it takes the cloned undo segment header so far back that it takes our transaction table slot back to sequence 999 – and the job is done, we can now check the actual commit SCN. (Or, if we’re unlucky, we might receive an ORA-01555 before we get there)
So – no changes to the t1 table during the query, but lots of undo records read because OTHER tables have been changing.
Footnote:
In my example the tablescan used direct path reads – so the blocks that went through delayed block cleanout were in private memory, which means they weren’t in the buffer cache and didn’t get written out to disc. When I flushed the buffer cache (again to emulate aging our of undo blocks etc.) and repeated the tablescan Oracle had to go through all that work of creating read consistent transaction tables all over again.
Shoney’s Hit By Apparent Credit Card Breach
Krebs on Security
It’s Friday, which means it’s time for another episode of “Which Restaurant Chain Got Hacked?” Multiple sources in the financial industry say they’ve traced a pattern of fraud on customer cards indicating that the latest victim may be Shoney’s, a 70-year-old restaurant chain that operates primarily in the southern United States.

Shoney’s did not respond to multiple requests for comment left with the company and its outside public relations firm over the past two weeks.
Based in Nashville, Tenn., the privately-held restaurant chain includes approximately 150 company-owned and franchised locations in 17 states from Maryland to Florida in the east, and from Missouri to Texas in the West — with the northernmost location being in Ohio, according to the company’s Wikipedia page.
Sources in the financial industry say they’ve received confidential alerts from the credit card associations about suspected breaches at dozens of those locations, although it remains unclear whether the problem is limited to those locations or if it extends company-wide. Those same sources say the affected locations were thought to have been breached between December 2016 and early March 2017.
It’s also unclear whether the apparent breach affects corporate-owned or franchised stores — or both. In last year’s card breach involving hundreds of Wendy’s restaurants, only franchised locations were thought to have been impacted. In the case of the intrusion at Arby’s, on the other hand, only corporate stores were affected.
The vast majority of the breaches involving restaurant and hospitality chains over the past few years have been tied to point-of-sale devices that were remotely hacked and seeded with card-stealing malicious software.
Once the attackers have their malware loaded onto the point-of-sale devices, they can remotely capture data from each card swiped at that cash register. Thieves can then sell the data to crooks who specialize in encoding the stolen data onto any card with a magnetic stripe, and using the cards to buy gift cards and high-priced goods from big-box stores like Target and Best Buy.
Many retailers are now moving to install card readers that can handle transactions from more secure chip-based credit and debit cards, which are far more expensive for thieves to clone. Malware that makes it onto point-of-sale devices capable of processing chip card transactions can still intercept data from a customer’s chip-enabled card, but that information cannot later be used to create a cloned physical copy of the card.
Character selectivity
Oracle Scratchpad
A recent OTN posting asked how the optimizer dealt with “like” predicates for character types quoting the DDL and a query that I had published some time ago in a presentation I had done with Kyle Hailey. I thought that I had already given a detailed answer somewhere on my blog (or even in the presentation) but found that I couldn’t track down the necessary working, so here’s a repeat of the question and a full explanation of the working.
The query is very simple, and the optimizer’s arithmetic takes an “obvious” strategy in the arithmetic. Here’s the sample query, with the equiavalent query that we can use to do the calculation:
select * from t1 where alpha_06 like 'mm%'; select * from t1 where alpha_06 >= 'mm' and alpha_06 < 'mn';
Ignoring the possible pain of the EBCDIC character set and multi-byte national-language character sets with “strange” collation orders, it should be reasonably easy to see that ‘mn’ is the first string in alphabetical order that fails to match ‘mm%’. With that thought in mind we can apply the standard arithmetic for range-based predicates assuming, to stick with the easy example, that there are no histograms involved. For a range closed at one end and and open at the other the selectivity is:
( ( 'mn' - 'mm') / (high_value - low_value) ) + 1/num_distinct
The tricky bits, of course, are how you subtract ‘mm’ from ‘mn’ and how you use the values stored in the low_value and high_value columns of view user_tab_cols. So let’s generate the orginal data set and see where we go (running on 12c, and eliminating redundant bits from the original presentation):
rem
rem Script: selectivity_like_char.sql
rem Author: Jonathan Lewis
rem Dated: Sep 2013
rem
execute dbms_random.seed(0)
create table t1 nologging as
with generator as (
select rownum id
from dual
connect by rownum <= 1000
)
select
cast(dbms_random.string('l',6) as char(6)) alpha_06
from
generator,
generator
where
rownum <= 1e6 -- > comment to avoid WordPress formatting issue
;
execute dbms_stats.gather_table_stats(user,'t1',method_opt=>'for all columns size 1')
column low_value format a32
column high_value format a32
select
column_name,
num_distinct,
density,
low_value,
high_value
from
user_tab_cols
where
table_name = 'T1'
order by
column_name
;
select min(alpha_06), max(alpha_06) from t1;
set autotrace traceonly explain
select
*
from
t1
where
alpha_06 like 'mm%'
;
set autotrace off
It will probably take a couple of minutes to generate the data – it’s 1M random strings, lower-case, 6 characters fixed – and will take up about 12MB of space. Here are the results from the stats and min/max queries, with the execution plan for the query we are testing:
COLUMN_NAME NUM_DISTINCT DENSITY LOW_VALUE HIGH_VALUE
-------------------- ------------ ---------- -------------------------- --------------------------
ALPHA_06 1000000 .000001 616161616E72 7A7A7A78747A
MIN(AL MAX(AL
------ ------
aaaanr zzzxtz
Execution Plan
----------------------------------------------------------
Plan hash value: 3617692013
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 157 | 1099 | 265 (20)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T1 | 157 | 1099 | 265 (20)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ALPHA_06" LIKE 'mm%')
Given that there are power(26,6) = 308,915,776 different combinations available for lower-case strings of 6 charactgers it’s not too surprising that Oracle generated 1M different strings, nor is it particularly surprising that the lowest value string started with ‘aaa’ and the highest with ‘zzz’.
So how do we get 157 as the cardinality for the query or, to put it another way, how do we get 0.000157 as the selectivity of the predicate. We need to refer to a note I wrote a few years ago to help us on our way (with a little caveat due to a change that appeared in 11.2.0.4) – what number would Oracle use to represent ‘mm’ and the other three strings we need to work with ?
According to the rules supplied (and adjusted in later versions) we have to:
- pad the strings with ASCII nulls (zeros) up to 15 bytes
- treat the results as a hexadecimal number and convert to decimal
- round off the last 21 decimal digits
We can model this in SQL with a statement like:
SQL> column dec_value format 999,999,999,999,999,999,999,999,999,999,999,999
SQL> select round(to_number(utl_raw.cast_to_raw(rpad('aaaanr',15,chr(0))),'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'),-21) dec_val from dual;
DEC_VAL
------------------------------------------------
505,627,904,294,763,000,000,000,000,000,000,000
1 row selected.
As an alternative, or possibly a cross-check, I created a table with a varchar2(6) column, inserted the four values I was interested in and created a histogram of 4 buckets on the column (there’s a suitable little demo at this URL) and got the following endpoint values:
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- ------------------------------------------------
1 505,627,904,294,763,000,000,000,000,000,000,000
2 568,171,140,227,094,000,000,000,000,000,000,000
3 568,191,422,636,698,000,000,000,000,000,000,000
4 635,944,373,827,734,000,000,000,000,000,000,000
Once we’ve got these numbers we can slot them into the standard formula (not forgetting the 1/1,000,000 for the closed end of the predicate) – and to save typing I’m going to factor out 10^21 across the board in the division:
Selectivity = (568,191,422,636,698 – 568,171,140,227,094) / (635,944,373,827,734 – 505,627,904,294,763) + 1/1,000,000
Selectivity = 20,282,409,604 / 130,316,469,532,971 + 1/1,000,000
Selectivity = 0.00015564 + 0.000001 = 0.00015664
From which the cardinality = (selectivity * num_rows) = 156.64, which rounds up to 157. Q.E.D.
Black Bird Cleaner, una herramienta ligera para limpiar y optimizar Windows

No es la primera vez que en Genbeta hablamos sobre programas para optimizar el sistema operativo. En otras ocasiones ya hemos hablado sobre las bondades de software como System Ninja en el caso de Windows, o Stacer en el de Linux. Hoy vamos a hablar de Black Bird Cleaner, una herramienta de limpieza y optimización para Windows que hasta ahora había pasado desapercibida para nosotros.
El programa se puede descargar y usar gratuitamente, si bien hay una versión de pago. En este sentido, no se diferencia mucho de otras soluciones similares. Lo que sí es interesante es el poco espacio de disco que ocupa, apenas un megabyte.
La herramienta cuenta con una interfaz simple que organiza sus funciones en distintas pestañas, que pasamos a enumerar y a explicar brevemente a continuación:
- Cleaning. En esta pestaña podrás limpiar las distintas cachés de tu sistema operativo, así como archivos temporales y ficheros residuales. Vale la pena señalar que puede detectar y limpiar la “basura” de hasta 50 navegadores.
- PC Optimization. Aquí se listan algunos ajustes básicos, como liberar memoria RAM, optimizar el sistema de archivos o acelerar el apagado del PC, así como buscar archivos de instalación que tengas guardados en el PC.
- Disk Analyzer. Con esta función se busca en todos los discos duros del ordenador los archivos más grandes, que se pueden eliminar haciendo clic con el botón derecho encima del archivo en cuestión.
- Service Manager. Se trata de una función similar a la pestaña “Servicios” del Administrador de Tareas, si bien es más limitada que la nativa de Windows y, si no se maneja con cuidado, puede “romper” la instalación o estropear el arranque del sistema operativo.
- System Information. En esta perstaña veremos una serie de detalles ordenados acerca de nuestro ordenador. Contiene un montón de datos que se pueden consultar, si bien para usuarios finales muchos de ellos no serán seguramente de utilidad. Ahora bien, para usuarios con un perfil mucho más técnico seguramente sí serán de ayuda.
Por las pruebas que hemos podido realizar, el programa es poderoso teniendo en cuenta su tamaño. Está muy bien que intente ir más allá que otras herramientas con las que compite, así como que cuente con ciertos ajustes que pueden resultar de utilidad a todos los usuarios.
Ahora bien, dentro de todo esto hay una parte negativa: en algunos puntos un usuario final puede perderse si decide ir más allá de realizar una limpieza del disco duro. No se trata de un programa para todo el mundo, y si te animas a probarlo te recomendamos que procedas con mucho cuidado. Como ya dijimos antes, quizá los usuarios con un perfil más técnico se sientan más cómodos con él.
Más información | Black Bird Cleaner
En Genbeta | Siete herramientas gratis para borrar de forma segura tus discos duros HDD o SSD
También te recomendamos
¿Qué pasa si tengo el cortafuegos de Windows desactivado?
Cómo cambiar el aspecto del puntero del mouse en Windows 10
7 trucos rápidos para cuidarte el rostro (sin dejarte la piel ni el presupuesto)
–
La noticia Black Bird Cleaner, una herramienta ligera para limpiar y optimizar Windows fue publicada originalmente en Genbeta por Sergio Agudo .
Windows 2010 actualización Adware AntiSpyware antivirus

Bitelia
2/3/10 9:03 AM
Vicente Juan
Windows 2010 actualización Adware AntiSpyware antivirus aplicacion archivos Chat computadora configuración contraseñas cookies correo correo electronico Cortafuegos Desactivar firewalls Hipertextual Labs HTTP información Internet malware Mensajería Instantánea Microsoft Windows navegador privacidad privada protección reiniciar Seguridad Software software malicioso spyware tiempo real troyanos usuario virus Windows Live Messenger Windows Messenger
Durante el pasado verano, entre los lectores de Bitelia, propusimos escoger al mejor antivirus para la familia Windows. En el resultado de las votaciones se impuso el popular NOD 32, pero la aplicación de seguridad de Kaspersky logró un meritorio segundo lugar con vuestros votos. Desde Hipertextual Labs queremos indagar más a fondo, profundizar en las prestaciones del nuevo Kaspersky Anti-Virus 2010.
Antes de iniciar la instalación de la aplicación, y después de aceptar los términos del contrato de licencia de usuario final, Kaspersky Anti-Virus 2010 explica las condiciones de participación en Kaspersky Security Network. Este proyecto recopila una selección de datos sobre la seguridad y el uso de las aplicaciones, y transfiere estos datos a Kaspersky Lab para su análisis. El objetivo bien intencionado es contribuir a identificar las nuevas amenazas que surgen y localizar su origen. Pero el envío de los datos, por temor a nuestra propia privacidad, es voluntario y el usuario puede desactivar la opción de recopilación desde la entrada Participación del apartado de Configuración.
La instalación personalizada permite escoger entre 7 subcategorías, 7 módulos que se encargan de distintas prestaciones de la aplicación. El núcleo del programa y tareas de análisis permite realizar un análisis en profundidad de tu equipo, para detectar y eliminar software peligroso para tu seguridad. Antivirus de archivos permite analizar todos los archivos de tu equipo cuando éstos son ejecutados, en tiempo real. Antivirus de correo, como su propio nombre describe, supervisa todos los mensajes entrantes y salientes de tu cliente de correo electrónico. Antivirus internet bloquea los virus que intentan entrar en tu computadora a través del protocolo HTTP. Antivirus para chat analiza el tráfico que genera tu cliente de mensajería instantánea (Windows Messenger y demás clientes). Protección proactiva combate las amenazas desconocidas, supervisa los cambios realizados sobre el registro del sistema y comprueba los comportamientos sospechosos de los programas que se están ejecutando. Y Teclado virtual protege frente a la lectura de información privada, como contraseñas, que puedan ser capturadas por keyloggers. En total, 77MB de espacio en disco se necesitan.
En mi computadora hay varias herramientas de seguridad instaladas: aplicaciones antivirus, programas para combatir el spyware y distintos cortafuegos (firewalls). Kaspersky Anti-Virus 2010 se quejó primero por tener instalados ClamWin Free Antivirus y SuperAntiSypware Free Edition. Para continuar la instalación, me obligó a desinstalarlos previamente y reiniciar el equipo. A continuación (ya me extrañaba a mi) detectó otros dos antivirus, Avira Antivir y Dr. Web, y también me obligó a desinstalarlos manualmente y volver a reiniciar. Al tercer intento pude instalar Kaspersky Antivir normalmente, pero con tres antivirus menos y una herramienta antispyware menos instalada en mi equipo. Me sorprendió que no detectara el antivirus AVG, también instalado en mi computadora. El obligar a desinstalar aplicaciones supuestamente incompatibles para poder continuar, es una mala práctica que también exigen otras soluciones de seguridad como Panda Security. Si no activas los módulos residentes de monotorización de amenazas en tiempo real, las distintas herramientas de protección no tienen porqué interferir unas con otras.
Para el usuario más inexperto, la herramienta configura los distintos parámetros para obtener un nivel de seguridad adecuado. Pero si deseas ajustar la protección de tu equipo, puedes decidir tú mismo cómo trabajará Kaspersky Antivir 2010. Respecto al módulo de actualización puedes escoger entre actualizaciones automáticas (recomendado), planificarlas periódicamente en el tiempo, o realizarlas tú mismo manualmente. Si varias personas usan la misma computadora, y no te fías, puedes activar una protección extra sobre el propio programa, una contraseña para evitar que el resto de usuarios pueda modificar la configuración que tú has establecido. Uno de los apartados más interesantes es clasificar las distintas categorías de software malicioso y elementos de riesgo a tratar: virus y gusanos (malware), troyanos, cookies publicitarias (adware), marcadores de conexión automáticos (auto-dialers), archivos comprimidos sospechosos y otros elementos potencialmente peligrosos e indeseables.
Desde la pestaña Protección supervisas el estado de protección de todo el sistema: la mayor o menor protección de los archivos instalados en el ordenador, la seguridad del sistema frente a los posibles intrusos y la propia privacidad de uno mismo. Algunos de los elementos a proteger requieren adquirir Kaspersky Internet Security 2010 para activarse. Desde el apartado Analizar mi equipo puedes empezar un análisis completo de todo tu sistema, uno más rápido sólo de los apartados más críticos y vulnerables, escoger tu mismo qué objetos analizar y cuáles no o buscar vulnerabilidades en el equipo por culpa del software de terceros (de otros fabricantes y desarrolladores distintos).
Desde la sección Actualizaciones mantienes al día la base de datos que contiene las vacunas frente a los nuevos virus que surgen todos los días, y los módulos de aplicación se renuevan para afinar su eficacia. Y desde Seguridad+ dispones de varias herramientas avanzadas, y servicios adicionales, para una mayor protección del equipo. Tienes un teclado virtual que te protege contra la lectura de información privada (como contraseñas), la posibilidad de crear un disco de rescate, ajustar tu navegador preferido, solucionar varios problemas de configuración de Microsoft Windows e, incluso, borrar todos tus rastros privados de actividad, como también realiza por ejemplo la herramienta CCleaner.
Conclusiones
9/10
La solución contra los virus propuesta por Kaspersky continúa innovando y ofreciendo las técnicas más completas para proteger tu equipo. En un mismo programa intenta agrupar todas las herramientas necesarias para combatir todos los frentes inseguros, que son muchos y muy complicados de defender. Las herramientas se encuentran agrupadas, y sobre el interfaz cada una dispone de una breve descripción que clarifica su manejo. La traducción al español simplifica su uso y se agradece.
Para mi, el problema más grave que padecían anteriores versiones de la solución de Kaspersky era su desmesurado consumo de recursos. Las nuevas versiones de los programas más populares, como puedan ser la herramienta de grabación Nero o la suite ofimática OpenOffice, al incrementar de versión también han aumentando notablemente su consumo y exigencia de recursos. Pero, en esta nueva versión de Kaspersky Anti-Virus 2010, sus exigencias de funcionamiento se han reducido y eso beneficia (lógicamente) al propio rendimiento del sistema. Si la protección en tiempo real de un antivirus exige tantos requerimientos que apenas puedes trabajar con tu máquina, la solución antivirus se convierte en un problema. Felizmente, en esta nueva versión 2010, Kaspersky ha solventado también esta papeleta.
Golang SSH Security

Golang SSH Security https://bridge.grumpy-troll.org/2017/04/golang-ssh-security/
950’s Tax Preparation
950’s tax preparation: plugboard programming with an IBM 403 Accounting Machine
http://www.righto.com/2017/04/1950s-tax-preparation-plugboard.html
Alan Turing.

Hoy 23 de junio, además de celebrar el final de solsticio de verano y la noche de San Juan, también recordamos el nacimiento de uno de los padres de las Ciencias de la Computación y uno de los grandes criptólogos que conoció el siglo XX: Alan Turing. Alan Mathison Turing, que nació el 23 de junio de 1912 en Londres y murió el 7 de junio de 1954 en Cheshire, fue un matemático, criptógrafo, filósofo y un teórico de la computación que trabajó, durante la Segunda Guerra Mundial, en el equipo que descrifró el código Enigma de la Alemania Nazi y que, tras la guerra, diseñó uno de los primeros computadores digitales programables y publicó uno de los primeros trabajos sobre inteligencia artificial.
Desde muy joven, Turing siempre mostro especial interés en las matemáticas y el cálculo, destacando estas habilidades en su época escolar frente al resto de disciplinas. Esta predilección por las matemáticas frente a otras disciplinas le llevó a suspender sus exámenes finales y a ingresar en la universidad que había elegido como segunda opción: el King’s College de la Universidad de Cambridge, lugar en el que se quedó y en 1935 obtuvo una plaza como profesor.
Al año siguiente, Turing editó un trabajo publicado por la Sociedad Matemática de Londres: On computable numbers, with an application to the Entscheidungsproblem, un trabajo que presentó un modelo formal de computador, la máquina de Turing, que trazaba una línea que dividía los problemas matemáticos en dos grupos, los que podían resolverse mediante un computador y los que no podían ser resueltos por una máquina. Este modelo teórico y su análisis de complejidad de algoritmos se sigue usando hoy en día, por ejemplo, en el mundo del Álgebra (los problemas P y NP). Durante 1937 y 1938, Turing realizó su doctorado en la Universidad de Princeton, gracias a que sus trabajos llamaron la atención de John von Neumann, momento en el que, durante la defensa de su tesis, introdujo el término hipercomputación.

Al estallar la Segunda Guerra Mundial, Alan Turing fue reclutado, junto a otros matemáticos, por el ejército británico para descifrar los códigos criptográficos alemanes, que procedían de la famosamáquina Enigma. Durante estos años, Turing colaboró en el diseño de una máquina, construida a base de relés, denominada Bombe cuya función era descifrar los códigos alemanes. Además, con el objeto de mejorar las máquinas descifradoras, sentó las bases para poder construir la primera computadora electrónica, Colossus, realizada con válvulas de vacío y de la que se construyeron diez unidades desde 1943. Tras finalizar la guerra y por los servicios prestados (que salvaron muchas vidas en el Atlántico), le fue concedida la Orden del Imperio Británico en 1946.
Al terminar la guerra, Alan Turing se integró en las filas del Laboratorio Nacional de Física en el diseño del ACE (Motor de Computación Automática), un proyecto para competir contra el EDVAC americano (dirigido por von Neumann). En 1947, Turing concibió la idea de las redes neuronales, el concepto de subrutinas y las bibliotecas de software. En 1949 fue nombrado director del laboratorio de computación de la Universidad de Mánchester y trabajó en el diseño del lenguaje de programación de una de las primeras computadoras del mundo, laManchester Mark I. Fue en esta época, en 1950, cuando publicó uno de sus artículos más importantes, que sentó las bases de la inteligencia artificial, Computing Machinery and Intelligence, que comenzaba con una pregunta:
Propongo considerar la siguiente cuestión: ¿Pueden pensar las máquinas?
En este artículo, Alan Turing abordó el problema de la inteligencia artificial y propuso un experimento, conocido como la prueba de Turing, que definía una prueba estándar con la que poder catalogar si una máquina era “sensible” o “sintiente” y llegando a pronosticar que en el año 2000 las máquinas serían capaces de imitar tan bien a los humanos que, en un 70% de los casos, sería muy complicado averiguar si estábamos hablando con una máquina o con un ser humano (algo que no llegó a ocurrir pero que a todos nos recuerda a Blade Runner).

En 1952, en plena cúspide de su carrera, Alan Turing fue procesado por ser homosexual (que en esa época era delito en Inglaterra) y fue condenado o bien a la castración química o a un año de prisión. Optó por la castración química que le acarreó graves secuelas físicas y, en 1954, murió tras ingerir una manzana envenenada con cianuro, acto que fue considerado como suicidio en aquella época, si bien hay teorías que apuntan al asesinato.
Un triste final para todo un genio que sentó las bases de gran parte de nuestra actual tecnología y que, tal día como hoy, hubiese cumplido 99 años.
Imágenes: The Guardian, Wan Link Sniper y Wikipedia
Alan Turing, criptólogo y padre de la computación escrita en Bitelia el 23 June, 2011 por jjvelasco
Enviar a Twitter | Compartir en Facebook
![]()



")
